Word profiles
Introduction
Profile słów umożliwiają odnalezienie w tekście słownictwa, które często łączy się ze wskazanym słowem w związki składniowe określonego rodzaju. Na przykład rzeczownik oczy często jest modyfikowany przez przymiotnik niebieskie i często jest dopełnieniem bliższym czasownika zamknąć. Z kolei rzeczownik pies często pojawia się w koordynacji z rzeczownikiem kot. Otrzymane kolokacje charakteryzują język korpusu, tj. w korpusie reprezentatywnym dla standardowego języka polskiego będą się pojawiały głównie związki wynikające z ogólnych zależności semantycznych lub frazeologii, natomiast w korpusie dziedzinowym — związki wywodzące się z języka danej dziedziny, związki charakteryzujące styl autora lub jego sposób myślenia. Na przykład w korpusie ogólnym słowo funkcja będzie często określane przymiotnikiem podstawowa, zaś w korpusie matematycznym częściej pojawi się przymiotnik ciągła lub różnowartościowa. Można się też spodziewać, że przymiotnik robotniczy będzie występował z innymi kolokatami w korpusie z czasów PRL, a z innymi w korpusie współczesnym.
Note
Word profiles are only available for corpora which have the dependency annotation enabled.
Please note that, due to statistical reasons, the search quality is higher for large corpora (over 1 million tokens) and for relatively frequent words.
The process of calculating a word profile might take up to a few dozens seconds, depending on the size of the corpus and the frequency of the search word.
Usage
Profile słów są dostępne z poziomu ekranu Odpytaj korpus, karta Profile słów (1 na obrazku). W pole Słowo należy wpisać słowo, którego profil chcemy wyliczyć.
Advanced search options
Po kliknięciu w ikonę koła zębatego (2) dostępne są również zaawansowane opcje wyszukiwania. Tworząc profil danego słowa, możemy wybrać, czy interesują nas wszystkie jego wystąpienia, niezależnie od formy w tekście (i.e. szukamy wg lematu), czy też chcemy zobaczyć jedynie kolokaty określonej formy danego leksemu (np. rzeczownika psy, a więc słowa w liczbie mnogiej, i mianowniku lub bierniku). Możemy też odfiltrować kolokaty, ustawiając minimalną liczbę wspólnych wystąpień w korpusie, ta funkcja pozwala ominąć pary, które rzadko się powtarzają, a uzyskały wysoki wynik ze względu na rzadkość ich poszczególnych elementów składowych w korpusie.
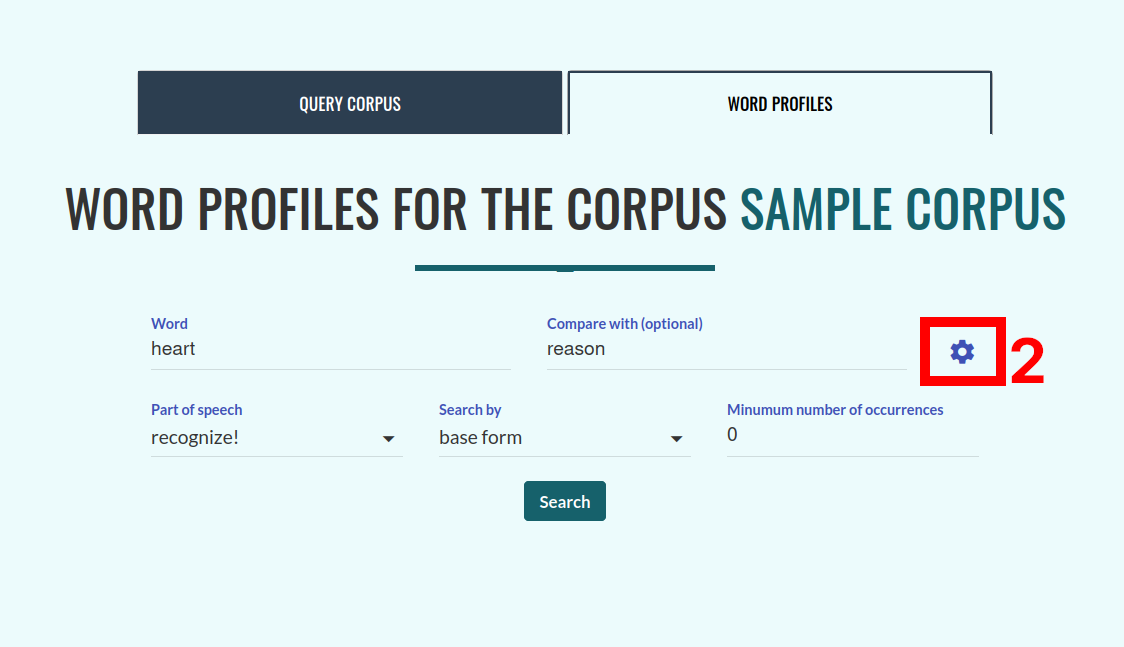
Formularz pozwalający doprecyzować parametry profilu słów: narzucić określoną interpretację pod względem klasy gramatycznej, określić, czy interesują nas wystąpienia wskazanej formy czy wszystkich form przynależących do danego leksemu, zastosować filtrowanie frekwencyjne lub słowo kontrastowe.
The results of the search are displayed in a table where each column represents one of the syntactic relationships characteristic of the word. The collocates in each column are arranged according to the strenght of the association (descending), independently of the rankings for the other syntactic relationships.
Note
The default value of the minimum number of occcurrences of each of the collocates depends on the size of the corpus – for corpora with at least 100 thousand tokens this number equals 3, while for other corpora it is 0.
Comparative profiles
Aplikacja umożliwia także tworzenie profili porównawczych. W tym celu należy wpisać do pola porównaj z drugie z interesujących nas słów. Wyszukiwanie porównawcze zakłada, że zadane słowa należą do tej samej klasy gramatycznej. Przygotowując tabelę, aplikacja weźmie pod uwagę różnicę wartości logDice słowa podstawowego, oraz słowa porównawczego dla każdego z kolokatów. Tabela jest automatycznie skracana do postaci w której ekstrahowane są trzy sekcje. Kolokaty wyraźnie preferujące pierwsze słowo, kolokaty neutralne (o wartościach różnicy logDice najbliższych 0) oraz kolokaty wyraźnie preferujące słowo porównawcze. Indeksy wierszy wpadających do każdej z tych sekcji są oznaczone innym kolorem.
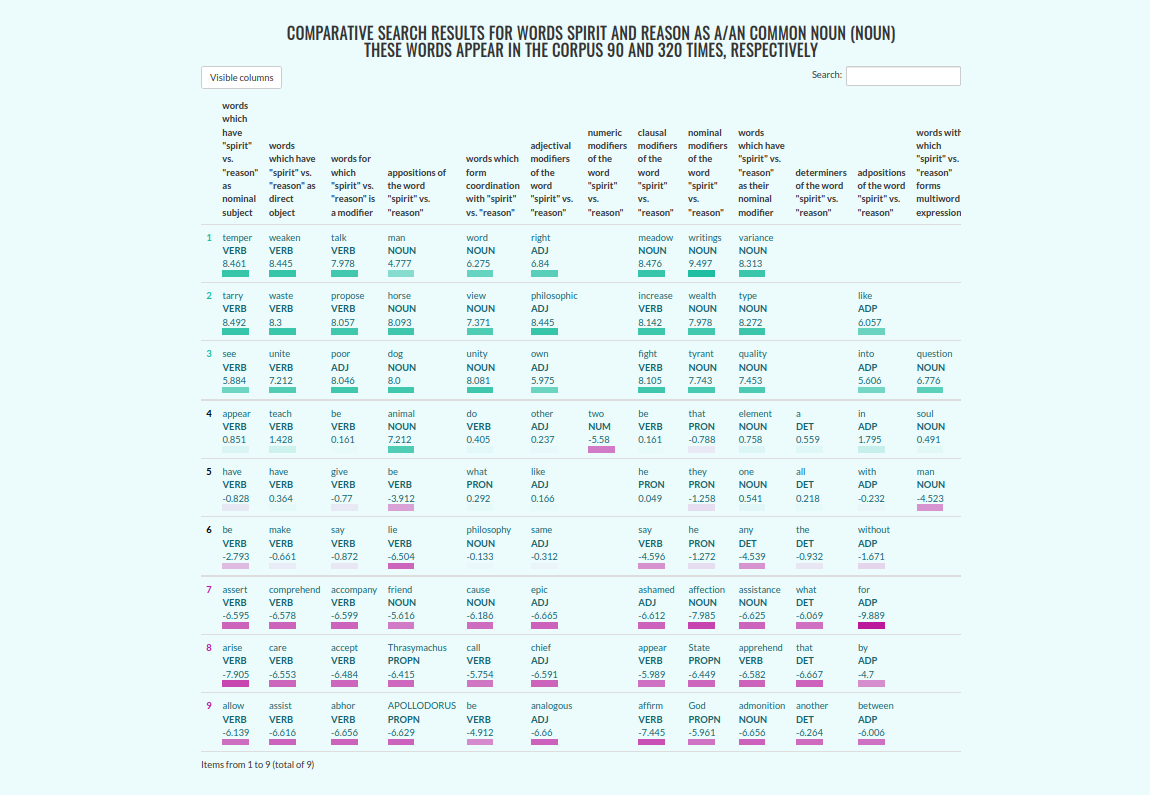
Comparative search results: spirit vs reason in Plato’s dialogues.
Clicking any of the collocates will generate a query that will allow to find all common occcurrences of the two terms.
Metrics used
Profile słów przedstawiają słownictwo często współwystępujące ze wskazanym słowem. Znaczenie słowa często jest tutaj formalizowane za pomocą miary logDice (i to te wartości są widoczne w tabeli). Miara ta przypisuje każdej z badanych par słów wynik będący – w pewnym uproszczeniu – stosunkiem liczby wystąpień w korpusie razem do sumy wystąpień w korpusie w ogóle (razem lub osobno) każdego ze słów. W ten sposób odfiltrowujemy takie słowa, które pojawiają się obok zadanego słowa często w wyniku tego, że same są bardzo częste (np. czasownik mieć, w odróżnieniu od czasownika zamykać).
The logDice is an interpretable measure used in collocate extraction. Its maximum value is 14 (when words always co-occur), and the difference between two values equal to 1 indicates that one of the collocations is twice as frequent as the other. The logDice value does not depend on the size of the corpus; it is thus possible to compare values calculated for different corpora.
Linguistic basis
Word profiles are calculated based on morphological annotation and dependency parsing results; hence this function is only available for corpora which have the dependency annotation layer. For each part of speech, there is a set of rules regarding potential collocates of the given word. For example, for nouns, the algorithm will search for verbs which take the given noun as their subject (a person believes) or their direct object (to protect a person), as well as nouns modified by the given noun (a person of commitment). By default, the set of rules is selected by the morphosyntactic class of the query word, recognised automatically by the application. However it is possible to impose a grammatical interpretation (e.g. walk as a noun, not as a verb). In the output table the collocates are displayed as lemmas.
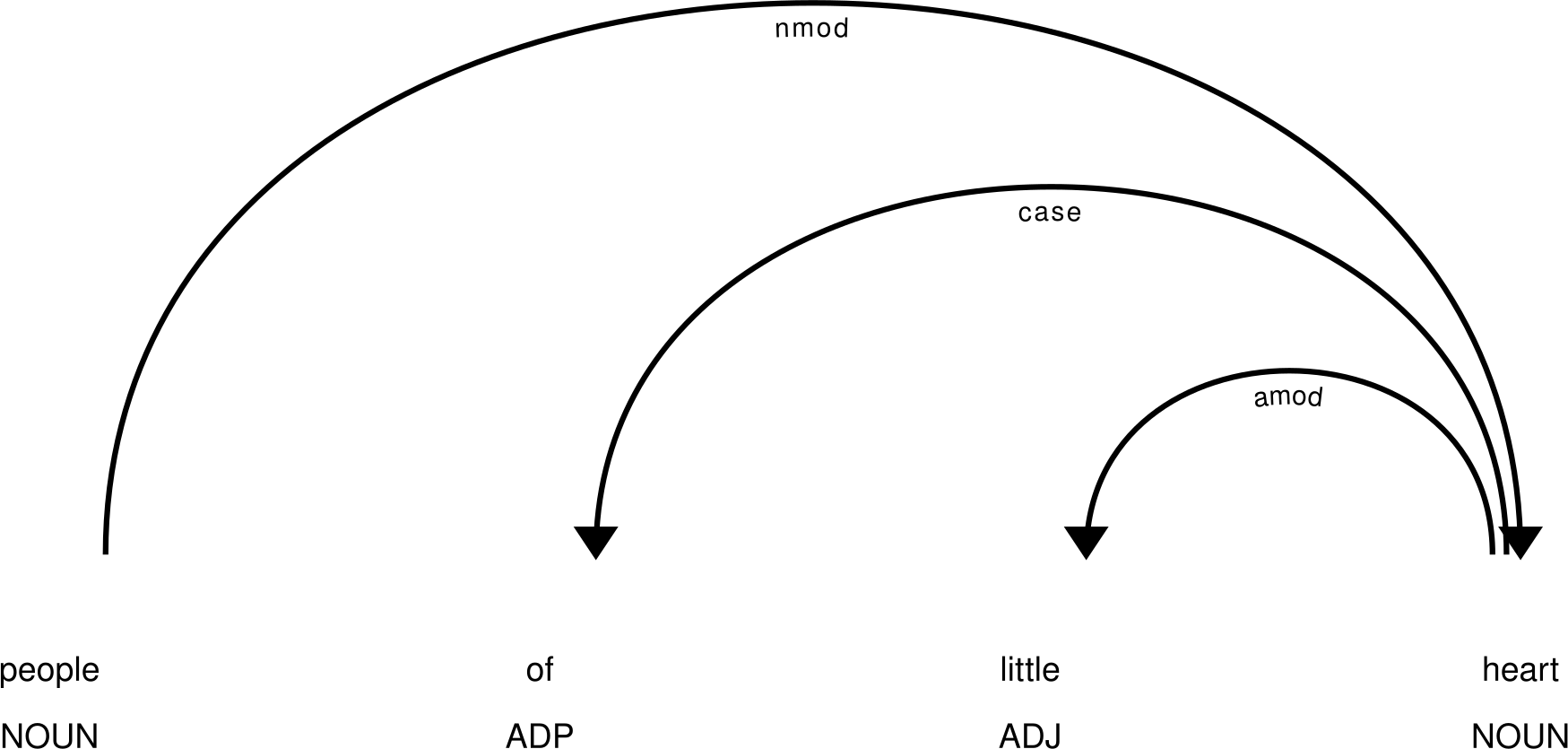
To calculate word profiles, dependency trees, such as the one shown in the picture, are used. In case of the word heart in the above example, little is an adjectival modifier of the word heart, and person is a word which has heart as its nominal modifier”
It should be noted that the search does not take negation into account. The occurences of a word will count towards a collocation regardless of whether they are within the scope of negating modifiers (e.g. not), conjuncts such as nor, lexical modifiers which are semantically close to negation (e.g. little in little influence), or are themselves formed via negation (e.g. unseen).
Coordination relationships
Coordinating conjunction is one of the most important relations. In the adopted grammatical formalism, coordination is represented as a subtree, in which the first component of the coordination is the head, and the subsequent units – the leaves. The head of the subtree is linked with its superordinate by the relation it would have if there were no conjuncts. Conjuncts, if there are any, are linked with the leaves by the cc relation. For example, in the sentence “The black dog and the cat are sleeping.” the word dog is connected with the verb sleep by the nsubj relation, the word cat is a subordinate of the word dog linked to it by the conj relation, and and is related to cat via a coordinating conjunction, with the cc tag, as in the example below.
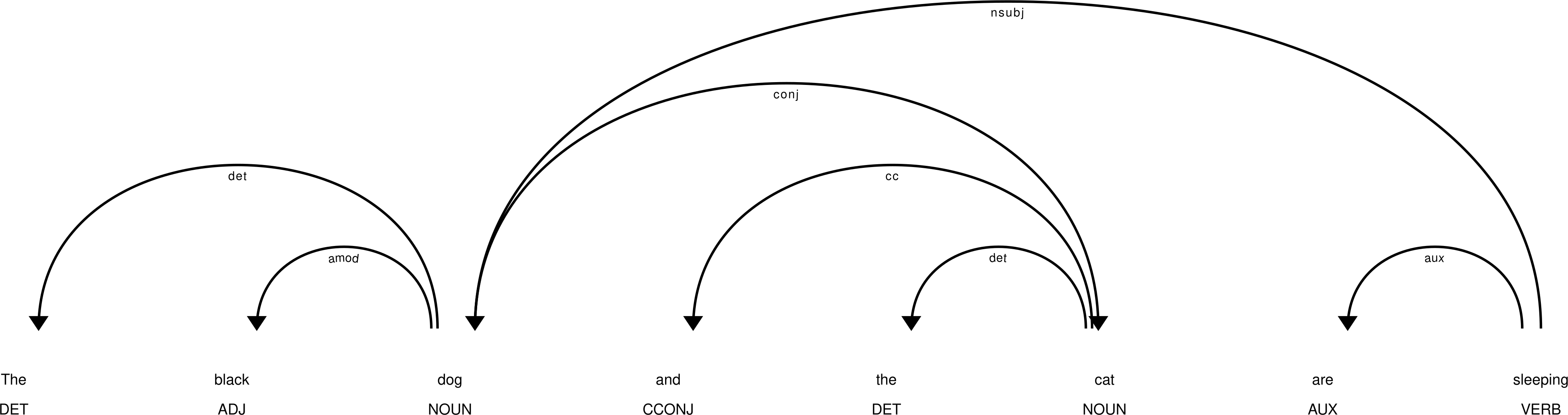
In order to include words which are the second or subsequent coordination components, in the collocate extraction system used coordination subtrees are handled in a special way. During the tree search the algorithm leaps over the root of the subtree, i.e. the first component of the coordination. Specifically, for the above example, both dog and cat will be recognised as subjects of the word sleep. Conversely, sleep will be recognized as a verb which has cat as its subject, even though these words are indirectly linked through the word dog.
This mechanism only applies to some of the possible relations. In the above example the word “black” will not be considered an adjectival modifier of the word “cat”. The relations that trigger the mechanism of coordination extension include:
for nouns (NOUN/PROPN):
words which have (…) as their nominal subject
words which have (…) as their direct object
words which have (…) as their indirect object
for verbs (VERB):
words which are the nominal subject of (…)
words which are the direct object of (…)*
words which are an indirect object of (…)
words which are the clausal subject of (…)
words which have (…) as their clausal subject
words which are a clausal modifier of (…)
słowa których dopełnieniem zdaniowym jest (…).

The representation of coordination and negation relationships in the syntactic formalism used. As the first coordination component is the direct subordinate of the obj relationship, the word character will be recognised as a direct object of “manifest”. Moreover, during the calculation the algorithm moves along the conj edges to additionally include the word position.