Corpus Query Language
This section comprises a guide into the Corpus Query Language, which takesinto account the different layers of annotation available in Korpusomat.
Tokenisation
Morphosyntactic tags are attributed to tokens, which correspond roughly to words. A token cannot be longer than an orthographic word (separated by spaces from other orthographic words, punctuation marks excluded), but it may sometimes be shorter. Segmentation rules may be different for different languages, and they depend on the decisions made by the creators of language resources for a given language (mainly treebanks), and by the creators of specific programming tools. For instance, in Polish language corpora (including the Polish National Corpus), it is customary to separate past verb forms from their so-called agglutinates (markers of person and number), and from the marker of the conditional mood (by particle). As a result, one word may be divided into two or three component parts, and each of them is given its own morphosyntactic tag. For example, the Polish verb jedlibyśmy (we would be eating) would be separated into three different tokens: [jedli][by][śmy], where jedli is the main verb (eat), by is the marker of the conditional mood, and śmy marks for the first person plural. In Korpusomat, the results of the tokenisation process may differ depending on the selected pipeline. Specifically, Stanza uses the same tokenisation model as is employed in the Polish National Corpus (it separates the agglutinate and the by particle), whereas spaCy considers past verb forms and conditional forms to constitute discrete tokens. This, however, is a rare and extreme case. Usually, the tokenisation of texts in a given language should be in line with the models adopted in the treebanks and the national corpora of this language, regardless of the pipeline employed.
Morphosyntactic tags
Wszystkie korpusy w Korpusomacie zawierają warstwę informacji morfosyntaktycznej zgodną ze specyfikacją Universal Dependencies. Informacja ta jest rozdzielona na dwie składowe: oznaczenie części mowy (tzw. UPOS — universal part of speech) oraz cechy morfosyntaktyczne (tzw. UFEATS — universal features). Obie te składowe (nazwy części mowy, nazwy cech morfoskładniowych i listy ich możliwych wartości) są opisane w dokumentacji na stronie projektu UD. Ponieważ z zasady jest to opis uniwersalny, każdy z konkretnych języków korzysta tylko z podzbioru cech morfologicznych i ich wartości.
Alongside morphosyntactic annotation based on the UD framework, an additional XPOS tag is available for most corpora. XPOS stores morphosyntactic information in line with the tagset employed in resources for a given language. Both pipelines return XPOS-tagged texts, but the precise forms of the tags depend on the decisions made by the creators of these specific tools and, in particular, by the creators of UD treebanks (specifically, technical descriptions of the tagset and the granularity of morphosyntactic descriptions may vary). As a result, XPOS tags do not have a single, standardised form. Usually, however, they comply with the tagsets employed in national corpora. If XPOS tags are not included in a given UD treebank (as is the case of Russian), Korpusomat will not be able to provide them (regardless of the pipeline employed). Sometimes, XPOS tags may differ depending on the pipeline, e.g. for Polish, using Stanza will return full morphosyntactic XPOS tags (as they are employed in Polish corpora), whereas spaCy will reduce them to the component which signals the grammatical class of the given word.
Corpus Query Language
The syntax of queries in MTAS in based on the Corpus Query Language (CQL), used in many other corpus browsers. This section describes the CQL as it is employed in Korpusomat.
MTAS is a multifunctional browser, ideal for corpora with many layers of annotation. The following is a guide to querying corpora indexed in Korpusomat, which are annotated at three different levels: morphosyntactic, syntactic, and the level of named entities. More general, basic information on MTAS is available at the project’s website.
Searching for tokens
The most basic unit in a corpus search is a token (an orthographic word). Usually, each element of a query has to be enclosed in square brackets. You can specify that you are searching for a token by adding the attribute orth. In this way, you can search for one or more (neighbouring) tokens. For example, the following query will return all instances where the words “green” and “ideas” appear next to each other:
[orth="green"][orth="ideas"]
You can also search for tokens by simply typing them into the search box:
green ideas
By default, the tool distinguishes between lowercase and uppercase letters. As a result, the following queries will return different results:
colorlessColorless
You can, however, use the attribute orth_lc (where lc stands for lower case) to change all uppercase letters in a token into lowercase letters. As a result, a query such as [orth_lc="colorless"] will return all instances of words such as colorless, Colorless, COLORLESS, and COlorLESs.
Queries may also be based on standard regular expressions, which employ special characters such as ?, *, +, ., ,, |, ,, [, ], (, ), as well as natural numbers (written in Arabic numerals), e.g. 0 or 21. While a more formal description of regular expressions is beyond the scope of this guide, the following examples illustrate the most essential rules of their use.
[orth="(pal|gal)"]
|is an equivalent to “or”: it matches all instances of one of two tokens (which are placed inside round brackets), such as gal or pal,[orth="[gp]al"]
placing p and g inside square brackets, followed by al, will return all instances of words beginning with either p or g, followed by al, in the exact same manner as the query above,
[orth="gall?"]
?makes the element it follows (or a group of elements placed inside round brackets) optional. The above query will return all instances of gal and gall,[orth="gal."]
full stop substitutes for one character only. This query will return all instances of tokens such as gall, gale, gala, gals, but not gal or galled,
[orth="gal.?"]
gal, gals, gale, gala, gall, but not galled,
[orth="t.t.."]
tokens with five characters, where t is the first and third character (e.g. tutor, totem, total),
[orth="w*i"]
asterisk repeats the preceding character or a group of characters any number of times. For instance, we can use it to search for tokens consisting of the letter w followed by zero or more letters i, such as w, wi, wii, wiii, etc.,
[orth="gal.*"]
tokens beginning with gal, such as gal or gallery,
[orth=".*al+"]
the plus sign has a similar function: it repeats the preceding character or a group of characters any number of times higher than zero. The above query will return tokens which end in al, all, alll, etc., but not in a, for example gal, regal, or gall,
[orth="wi{1,3}.*"]
w is followed by between 1 and 3 letters i, which are then followed by any number of characters. The results might include tokens such as wi, wii, and winter,
[orth=".*(ha){3,}.*"]
n,repeats the preceding character or a group of characters (placed inside square brackets) at least n times. For example, the above query will return tokens where ha is repeated at least three times, such as ahahaha or hahahaha,
Queries with different attributes
In order to find all forms of the word corpus, type in the following query:
[lemma="corpus"]
lemma is one of the many attributes which may form part of a query. It takes the basic, dictionary form of a word as its value. For instance, [lemma="sleep"] will return forms such as sleep, slept, and sleeping.
Similarly as in the case of the attribute orth, regular expressions may be used to form queries about lemmas. For example, the following
[lemma="p[ao]tent"]
will return all instances of tokens whose dictionary forms (lemmas) are either patent or potent.
You can also specify more than one attribute of your search item. For instance, if you wish to find all instances of the token cooler, but only in its adjectival meaning (i.e. the comparative form of the adjective cool), but you want to exclude those instances where cooler is used as a noun, the following query may be employed:
[orth="cooler" & lemma="cool"]
The following query, which instead excludes those instances where cooler is used as a noun, will return similar results:
[orth="cooler" & !lemma="cooler"]
While & is the operator of logical conjunction, a disjunctive formula is notated with |. Here are some examples of how the latter can be employed:
[lemma="sleep" | lemma="dream"]
returns all forms of the verbs sleep and dream; this query is equivalent to
[lemma="sleep|dream"],[lemma="sleep" | orth="dreaming" | orth="dreamer"]
returns all forms of the verb sleep, as well as all instances of the segments dreaming and dreamer,
[orth="cooler" & !(lemma="cool" | lemma="cooler")]
returns all instances of the token cooler which are neither forms of the lexeme cool, nor forms of the lexeme cooler.
In order to better understand the difference between the two operators - & and | - let us compare the following two queries:
[orth="cooler" & lemma="cool"]
[orth="cooler" | lemma="cool"]
The first query matches only tokens which are interpreted as forms of the lexeme cool. The second query matches all tokens of the word cooler, regardless of their interpretation (noun or adjective), as well as all forms of the lexeme cool, such as, among others cooling, coolest, and coolers.
A query may include as many attributes (with their values) as necessary, which may be connected using operators such as !, &, and |, as the examples above demonstrate. But a query without any conditions is also possible. The following query may be used to retrieve all tokens in the corpus.
[]
In other words, empty square brackets stand for any token. They can be used, for instance, to retrieve two specific tokens, which are separated by two unspecified tokens:
[orth="you"][][][lemma="sleep"]
This will retrieve multi-word items such as you can always sleep or you and I sleep.
You can also search for two tokens which are separated by up to n unspecified tokens. For example, the following query will return multi-word expressions, where you is separated from sleep by two, three, or four unspecified tokens:
[orth="you"][]{2,4}[lemma="sleep"]
The results will include expressions retrieved using the preceding query (you can always sleep and you and I sleep), as well as others, such as you can go to sleep or you and I will sleep.
Queries using morphosyntactic tags
The attribute upos (universal part of speech) takes as its values different grammatical classes; their symbols are listed here: https://universaldependencies.org/u/pos/index.html. You can use it, for example, to search for two adjacent nouns, both beginning with a:
[upos="NOUN" & orth="a.*"]{2}
Similarly as in the case of orthographic words and lemmas, you can also use regular expressions in queries about grammatical classes.
Furthermore, using the xpos attribute, words marked with tags specific for the given language may be retrieved. Here, too, regular expressions may be employed. For example, you can search for all singular neuter nouns in the nominative case in a corpus of Czech using the following query:
[xpos="NNNS1.*"]
In order to retrieve nouns of the same characteristics in a Polish corpus (using Stanza) you would need to type in the following query:
[xpos="subst:sg:nom:n.*"]
In both cases, the values of the xpos attribute are followed by .* to reflect the fact that each tagset may also include other categories, apart from those that are specified in each query (part of speech, number, gender, and case).
Thus, you can search for orthographic forms (attribute orth), lemmas (attribute lemma), and tokens belonging to specific grammatical classes (upos or, alternatively, xpos). You can also specify the values of different grammatical categories - such as gender or case - provided that they are included in the grammar of the language under the investigation. The layer of morphosyntactic features (UFEATS) of a given language treebank includes all of the categories that can be applied to the words of this language; their lists are available at <https://universaldependencies.org/u/feat/all.html>`__.
For instance, if the grammar of the language of the corpus includes the property of grammatical number, you can form the following queries:
[number="sing"]
matches all singular forms,
[upos="NOUN" & number="sing"]
matches singular common nouns,
[upos="NOUN" & !gender="fem"]
matches common nouns with the value of gender other than feminine (e.g. masculine and neuter for languages such as Polish, Czech, or Ukrainian),
[number="sing" & case="(nom|acc)" & gender="masc"]
matches singular nominative or accusative masculine forms (if the grammar of the given language has the categories of number, case, and gender).
The names of the categories can also be substituted by the universal attribute ufeat. For example, the following two queries will return the same results:
[upos="NOUN" & case="acc" & number="plur" & gender="fem"]
[upos="NOUN" & ufeat="acc" & ufeat="plur" & ufeat="fem"]
Visual CQL query builder
The visual CQL query builder may be employed to create simple queries. You can use it to define the attributes of each element of a query: part of speech, lemma, as well as values of all grammatical categories listed on the UD website: https://universaldependencies.org/u/feat/all.html. Different conditions may be included using the operators and (conjunction) and or (disjunction). Once each element of a query is defined, press the Save button. The query will now appear in the search bar, so that you can verify whether it is correct. Before pressing the Search button, you can define additional search parameters (this is optional): for instance, you can use metadata to limit your search.
Limiting the search to a sentence or a paragraph
In corpora indexed in Korpusomat, the units of organisation are sentences and paragraphs. You can use this division when building your queries, for example by limiting a query to a single sentence.
In order to limit a query, you need to add the keyword within, followed by <s/> or <p/>, depending on whether you want to limit it to a single sentence (<s/>) or paragraph (<p/>). For example, the following query matches sentences where the lemma sleep is separated from the token furiously by at least one, but no more than ten segments:
[lemma="sleep"][!orth="furiously"]{1,10}[orth="furiously"] within <s/>
Dodatkowo można również na elementy <s/> i <p/> nałożyć pewne
warunki dotyczące tego, czy zawierają segmenty innego typu. Przykładowo,
za pomocą następującego zapytania można znaleźć wszystkie wystąpienia
czasownika pomocniczego być w czasie przyszłym ograniczone do zdań
zawierających formę bezokolicznika:
[upos="AUX" & lemma="być" & tense="fut"] within (<s/> containing [verbform="inf"])
Intencją takiego zapytania jest odnalezienie (w przybliżeniu) wszystkich wystąpień konstrukcji czasu przyszłego złożonego, w których pojawia się bezokolicznik. Wśród wyników będą oczywiście również takie zdania, w których czas przyszły został utworzony z użyciem formy przeszłej czasownika, a bezokolicznik pełni w zdaniu inną funkcję gramatyczną. Można też sformułować zapytanie odwrotnie i zapytać o zdania, w których forma przeszła w ogóle nie występuje:
[upos="AUX" & lemma="być" & tense="fut"] within (<s/> !containing [tense="past"])
The full list of keywords which can be employed in an MTAS search is available here: <https://meertensinstituut.github.io/mtas/search_cql.html>`__. It is important to note, however, that not all of them will have their uses in Korpusomat.
Apart from tags marking elements of a text’s structure, such as <s/>, there are also tags marking their beginnings and ends, such as <s> and </s>, respectively. They will not retrieve any specific segments, but they may be used to further limit the search for an already specified segment. For instance, the query:
<s> [upos="NUM"]
will retrieve all instances of a numeral at the beginning of a sentence. A similar query:
[upos="NUM"][upos="PUNCT"]</s>
will retrieve all instances of a numeral followed by a punctuation mark at the end of a sentence.
The layer of syntax
Another layer of annotation is based on dependency parsing. A text uploaded by a user is automatically divided into sentences, which are then analysed syntactically, in line with the principles of the Universal Dependencies project. The following image shows an example.
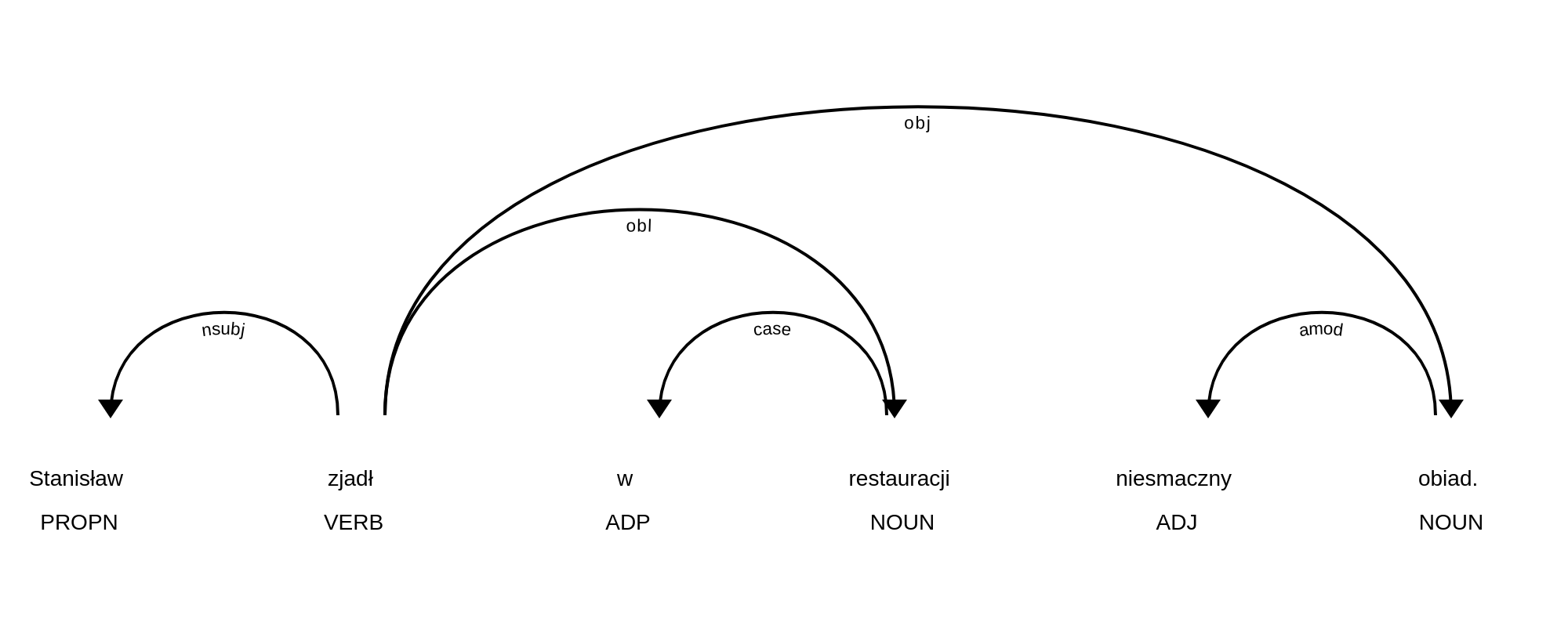
As MTAS is not designed to search for syntactic structures, it cannot be employed to index or search for full sentence diagrams. However, at the level of a token, Korpusomat indexes information about its syntactic head (specifically, the head’s lemma and inflectional class), and about the type of relation between these two elements. It also indexes their relative positions (in the linear order) and the distance between them (measured in tokens). As a result, one can search for simple syntactic structures as well as analytical discontinuous inflectional forms.
The following attributes are available at the level of syntactic annotation:
deprel— type of relation between a token and its syntactic head; its value may be one of the 65 dependency relations listed at <https://universaldependencies.org/u/dep/index.html>`__ (although the sets of values may differ between languages),head.upos— part of speech (UPOS) of the head of the given token,head.lemma— lemma of the head of the given token,head.ufeat— value of any morphological feature of the head of the given token,head.distance— distance from the token to its syntactic head,head.position— position (left- or right-branching) of the head with respect to the given token in a linear order.
As a result of adding these attributes to the Corpus Query Language, the user can easily find, for instance, all common nouns employed in the function of a direct object of a given verb:
[upos="NOUN" & deprel="obj" & head.lemma="dream"]
Or, alternatively, one can search for the verbs which take a specified noun as their direct object:
[deprel="obj" & head.upos="VERB" & lemma="idea"]
Należy jednak zwrócić uwagę, że w powyższym przykładzie wynikiem zapytania będą wystąpienia rzeczownika osoba, nadrzędne względem nich formy czasownikowe (finitywne i niefinitywne) będą się zaś znajdowały w lewym lub prawym kontekście wyników wyróżnione pismem pogrubionym. Można je jednak zgrupować i posortować względem ich częstości dzięki opcjom Statystyk.
The attribute coding for left- and right-branching of the syntactic head with respect to the given token allows the user to find examples of non-standard word order. For example, the following queries will retrieve instances when the verb is followed by its subject:
[deprel="nsubj" & head.position="left"]
or when the verb is preceded by its direct object:
[deprel="obj" & head.position="right"]
Similarly, a query which does not specify the position of the head, as in:
[upos="ADJ" & deprel="amod" & head.lemma="sleep"]
will match all adverbs modifying the verb sleep. In turn, specifying its position will limit the search to adverbs positioned to the left (furiously sleep) or to the right (sleep furiously) of the verb.
Thanks to the partial syntactic annotation, the user can search for elements of a phrase which remain in a relation of dependency, regardless of the fact that they may not necessarily be neighbouring words, but may, in fact, be separated by other segments. The attribute of distance further limits the search to instances where these elements are not neighbouring words:
[deprel="obj" & head.upos="VERB" & tense="past" & !head.distance="1"]
The above query will retrieve all words in the function of a direct object of a verb in the past tense, separated from the verb by at least one element.
Syntactic annotation may also be employed to search for passive forms of verbs:
[upos="AUX" & deprel="aux:pass" & head.upos="ADJ"]
którego dopasowaniem są słowa posiłkowe konstrukcji biernej połączone z formą imiesłowu
biernego (oznaczoną jako przymiotnik) relacją aux:pass.
The layer of named entities
The final layer of information added to texts indexed in Korpusomat is the layer of named entities. Named entities are one- or multi-word items designating people, places, institutions, etc. There is no single, universal standard for annotating named entities, nor is there a multilingual dataset annotated consistently for named entities. As a result, the values and their ranges at this layer of annotation vary depending on the pipeline as well as across languages within each pipeline. Furthermore, for some languages, models of annotation of named entities are not available.
The most basic commonly used set of labels for named entities consists of only four elements: PER (person), LOC (location), ORG (organisation), and MISC (miscellanea). It is available, within the Stanza pipeline, for Spanish, French, Russian, and Ukrainian, among others. However, some languages employ more detailed classifications. For instance, there are 18 values for the classification of named entities in English and Chinese. The visual CQL query builder provides the full list of values available for a given corpus. The following examples employ the simplest four-element classification.
Named entities, similarly to sentences and paragraphs, may cross segment boundaries. Therefore, the <ne /> tag may be used to refer to items marked as named entities. The rules regarding the use of slash also apply here:
<ne>marks the beginning of a string marked as a named entity,</ne>marks the end of a string marked as a named entity.
The following is the simplest query about named entities:
<ne />
It will retrieve all named entities of every type in the corpus. But the user can also limit the search to, for example, names of locations:
<ne="LOC" />
Similarly as in the case of sentences and paragraphs, it is possible to create queries about specific orthographic or morphosyntactic features of named entities. For example, the user may search for:
[upos="CCONJ"] within <ne="PER" />
names of organisations where segments are linked by a coordinate conjunction, such as Department for Culture, Media, and Sport or Organisation for Economic Cooperation and Development,
<ne="LOC" /> [upos="CCONJ"] <ne="LOC" />
— wystąpienia dwóch nazw geograficznych połączonych spójnikiem współrzędnym, np. Europa Zachodnia lub Skandynawia,
[orth="A.*"][orth="M.*"] fullyalignedwith <ne="PER" />
two neighbouring tokens starting with, for instance, T and M, and forming a person’s name, e.g. Theresa May, Thomas Mann.
Furthermore, information about the length of each named entity (measured in tokens) is available. The following query will return all named entities which consist of exactly three tokens:
<ne.len="3" />
odnajdzie wszystkie takie jednostki składające się z dokładnie trzech segmentów.
Using metadata to limit the search
Texts uploaded into Korpusomat are, by default, given four metadata labels: author, title, date of publication, and genre. This information is usually provided by the user, but the labels may also remain empty. The user may also add new labels.
The metadata may be used to limit corpus searches. In order to do so, press the Metadata button, define a constraint, and then press Add constraint. This process can be repeated in order to add more than one constraint.